'Twas brillig, and the slithy tovesThis assignment explores the use of the dictionary object to generate pronounceable nonsense words, known as pseudowords or logatomes, similar to those found in The Jabberwocky by Lewis Carroll, using three probabilistic models of word creation that become progressively more accurate.
Did gyre and gimble in the wabe;
All mimsy were the borogoves,
And the mome raths outgrabe.
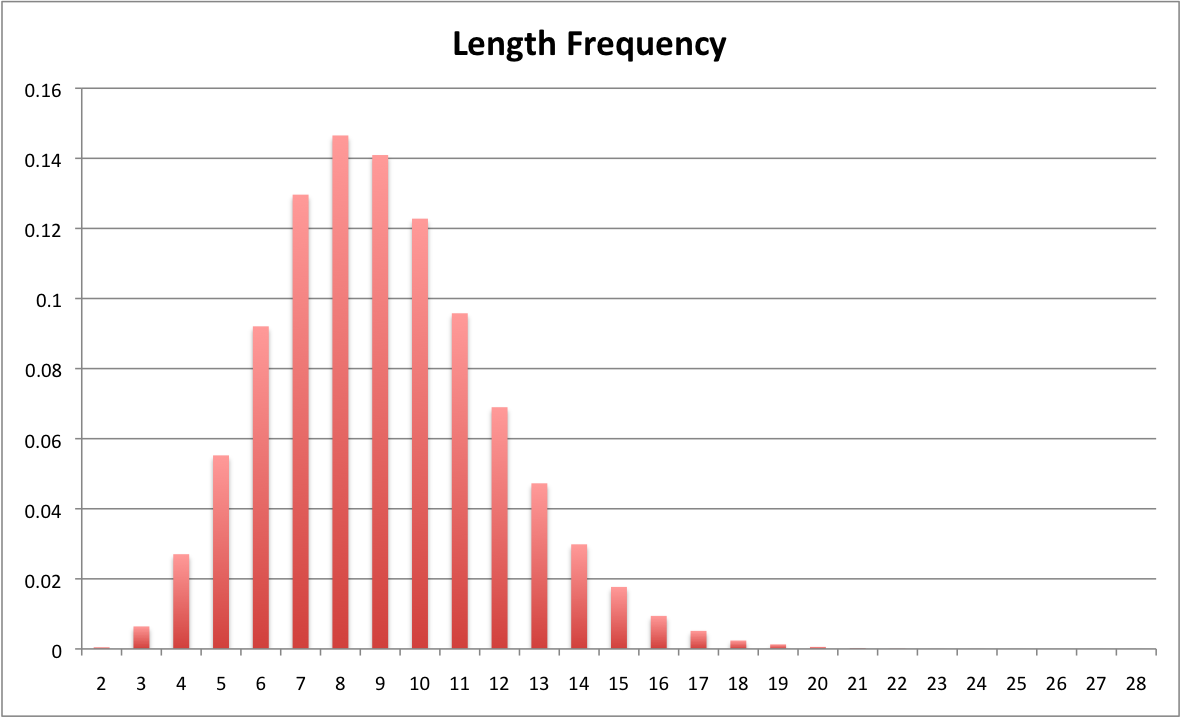
word_length
to calculate a histogram
of word lengths based on a comprehensive list of words in the English language. We can see in the
figure below that this is not a uniform distribution. This
function should return a dictionary with integer lengths as keys and the frequency counts as values.
Next, write a second function called proportionalprob that takes a
histogram as a parameter and returns a key proportional to the histogram counts. For example, if
words of length 4 comprised 17% of the word list, your function should return 4 on average 17% of the time.
Finally, write a function called nonsense that will bring in a count of how many words to
generate. Calculate the word length frequency dictionary, then for each word, randomly select a length,
and then uniformly select random characters for this word.
letter_freq which will
calculate a histogram dictionary with letters as keys and letter frequency counts as values.
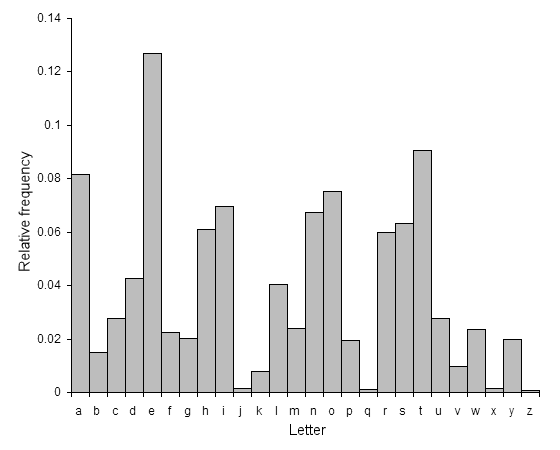
Revise your naive function above to use the proportional probability function twice, once for length, and then once for letters, to generate the words.
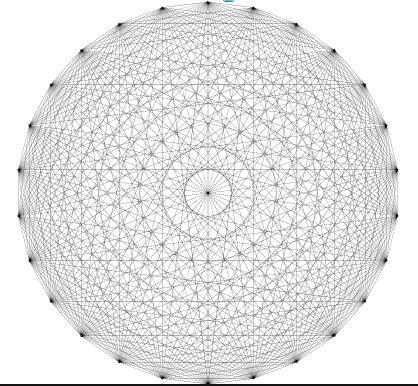
We start with a Markov Chain of order 1. The order of the Markov Chain is how many of these previous letters to use. This generates the graph above, where each letter is connected to every other letter, including itself, and the edges are the probability of choosing the connected letter next. If we also include "\n" as a possible character, our words will naturally terminate.
Write a function markov that brings in a word list and an order n.
This function will create a dictionary with the previous n letters of a word as the key,
and a second dictionary as the value. These inner dictionaries are similar to the previous letter
frequency dictionaries and can be used in the same way to generate the next letter. Revise your
function above to use this dictionary to generate words. When you generate a "\n" character,
start with the next word.

Experiment with your function to find the order which best creates nonsense words. What happens when the order is very large?