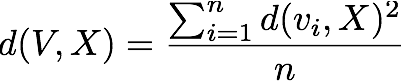
Your input vector data will be in a standard data format, where each line will start with the name of the vector, followed by the data for that vector. All vectors will be the same size.
For example, the greedy algorithm discussed in class for K-means is as follows:
kmeans(dataset, k):
Read in data vectors
Randomly select k data points to be centers of clusters
While the clusters have changed composition:
Asign every data point to it's nearest cluster center (euclidean distance)
Recalculate the center for each cluster as the average of all points in that cluster
The goal of K-means is to minimize the squared error distortion, which for a set V of data points and X of centers, is defined as
for the center X closest to each vi.
What do you believe is the optimal number of clusters?
Turn in your code and output from testing in your csc277 directory on the cs.centenary.edu server in a project 5 folder.