CSCI 270 - Lab 7 and 8
Markov Models
Materials
Lab 7
Markov Chains
When modern browsers like Chrome visit a webpage, there is sometimes an option to
automatically translate the text into English from another language. How does
the browser detect other languages? One way is to pass the text of the webpage through
prebuilt Markov chains for many languages, and determine which language has the
highest probability of generating this text.
Download the four classic books above, and learn the probabilities for a
Markov chain that models the adjacent letter patterns
found in each of the given languages. We will ignore the header and footer text
in the files, only focus on the actual book text.
Your states in the Markov chain will be each possible letter in any of
the four languages and the space character. The Markov chain should be fully connected,
so that any state can be followed by any other state. Use the concept of a
pseudocount to initialize every
possible observation to be 1, then increment these counts for the adjacent pairs
found in the text, and finally normalize your counts to be probabilities.
For simplicity, ignore all punctuation
and capitalization. You will
need to incorporate log probabilities.
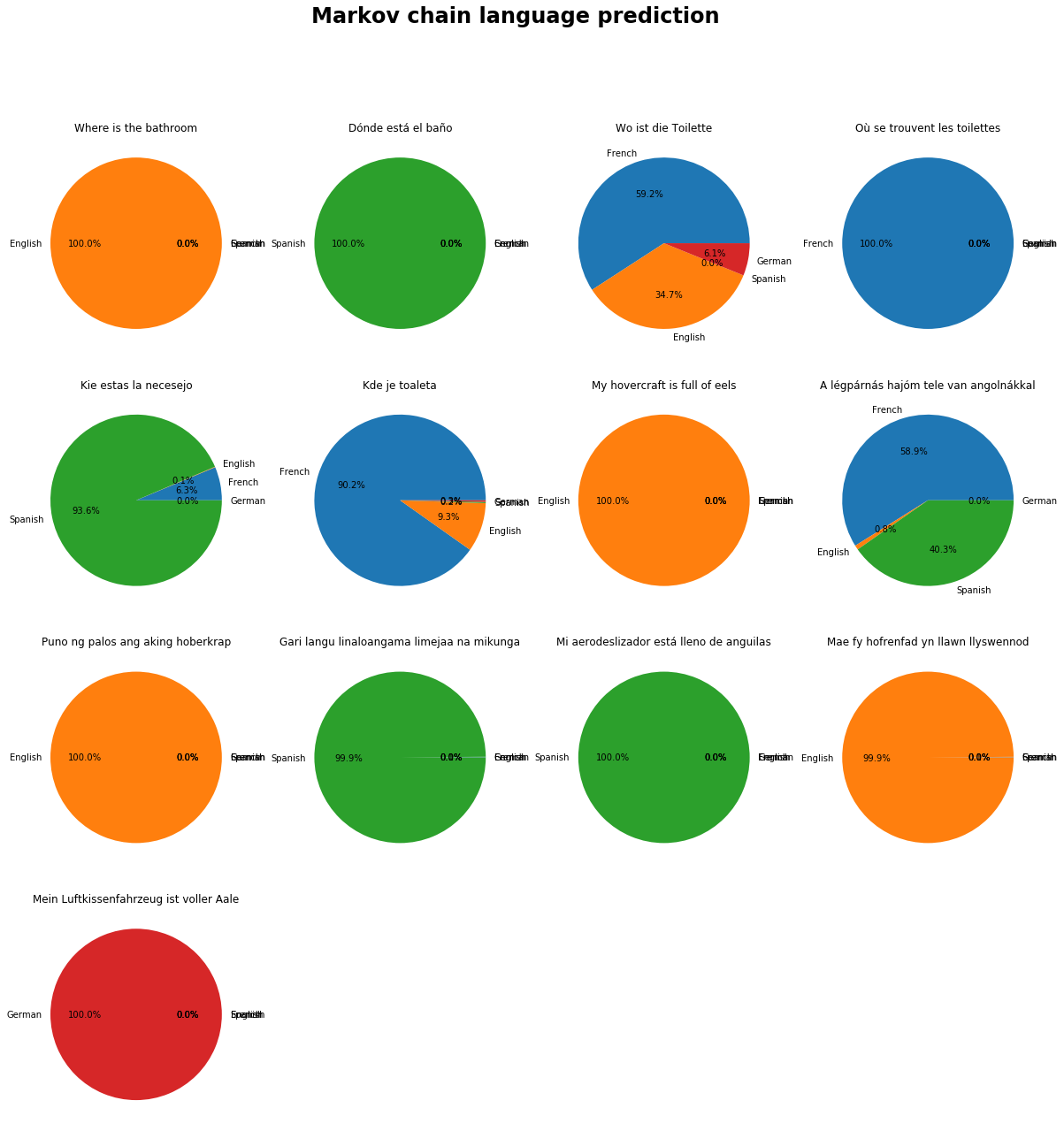
Use your learned Markov Chains to predict the language used in the following
phrases. Clearly show the probabilities found for each of the four possible languages.
- Where is the bathroom
- Dónde está el baño
- Wo ist die Toilette
- Où se trouvent les toilettes
- Kie estas la necesejo
- Kde je toaleta
- My hovercraft is full of eels
- A légpárnás hajóm tele van angolnákkal
- Puno ng palos ang aking hoberkrap
- Gari langu linaloangama limejaa na mikunga
- Mi aerodeslizador está lleno de anguilas
- Mae fy hofrenfad yn llawn llyswennod
- Mein Luftkissenfahrzeug ist voller Aale
Lab 8
Hidden Markov Models
We can also analyze languages and uncover syntactic properties using HMMs.
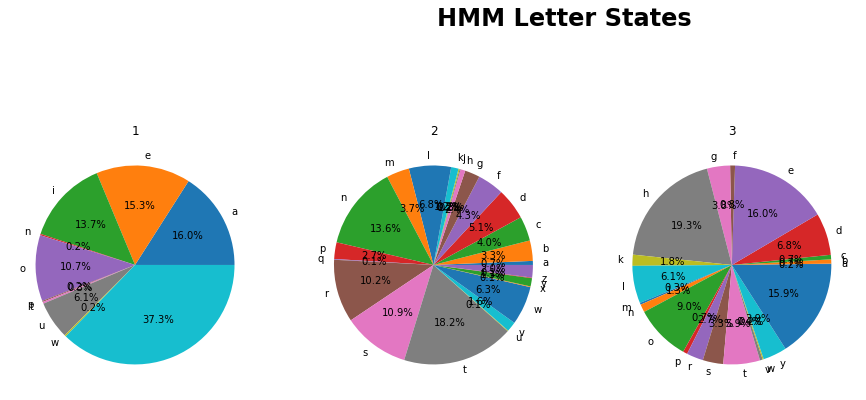
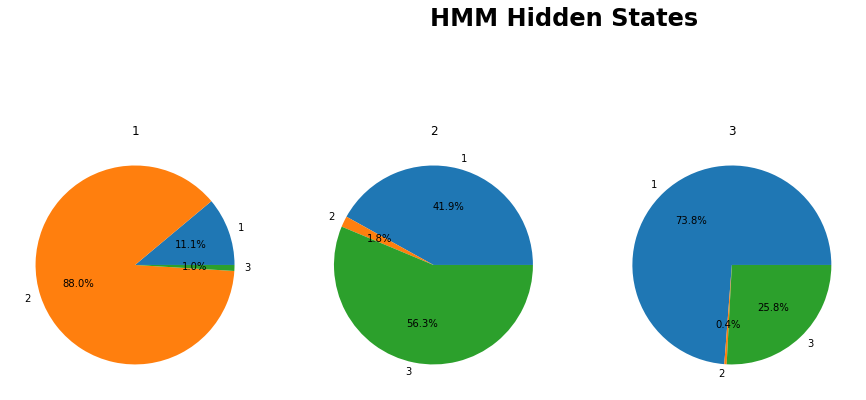
We can use the text from Alice in Wonderland and the Baum-Welsh Algorithm to learn the parameters
of a Hidden Markov Model with three
hidden states. Again, treat each letter as a state, ignore punctuation and capitalization,
but retain spaces. Initialize
your transition and emission probabilities randomly as discussed in class.
Treat each line of the text as a separate
sequence for training purposes.
Implement the FORWARD and VITERBI algorithm at the locations specified in the notebook.
What do you notice about the transition and emission probabilities of the states you
learned? Do they align with anything in English?
Use the Viterbi algorithm to determine the most probable
path for the following phrases:
- one does not simply walk into mordor
- stop trying to make fetch happen its not going to happen
- has anyone really been far even as decided to use even go want to do look more like
Food for Thought
Ideas similar to what we have examined in this lab can help us understand relationships between
different languages, and recover information from
dying
languages or interstellar
communication.